Choosing a Disaster Recovery solution over another is an important decision for any company, considering the serious impact an attack or disaster has on business profits.
Since more and more organizations and services are digitized, and the number of cyberattacks worldwide continue to rise, Disaster Recovery planning has become indispensable for ensuring business continuity. Therefore, as DR solutions come in many shapes, it is useful to keep some key aspects in mind to opt for the right one for each business.
But first things first!
Why is it important to have a DR solution?
The rise in the amount of disasters and cyberattacks, and the acceleration of digital transformation processes among organizations brings Disaster Recovery solutions into focus. As they are essential to guarantee normal business operations at all times regardless of any incident or attack that might impact a company’s main site. However, most organizations usually pay attention to it when it is too late.
The following numbers highlight the importance of DR solutions. Weekly cyberattacks on corporate networks increased by 38% globally in 2022, compared to 2021 — according to Check Point Research data. Besides, when looking closer at regional level, North America, Latin America and Europe were the regions experiencing the largest increases in 2022 — +52%, +29% and +26% respectively.
Key aspects to consider when choosing a Disaster Recovery solution
Choosing a Disaster Recovery solution adapted to the business needs is essential when building a DR strategy. Here are some important aspects to consider for success.

Recovery site
Let’s start with something as simple as having a site for recovering services in case of incident. It is to say, a secondary environment or data center where keeping operations uninterrupted in case of failure.
When choosing a disaster recovery site, organizations must usually decide if opting for a cold site, a warm site or a hot site, depending on their recovery objectives, budget, etc.
Cold sites
Firstly, a cold site consists of a rented space where operations can be restored in case of a disaster in the company’s primary environment. However, this option does not include any hardware or software.
Cold sites entail longer setup times to restore normal operations from the production to the recovery environment. Not only is it necessary to restore backups but also to install hardware. That is why it also requires a higher number of technical staff available to set the infrastructure up in case of emergency.
This is the cheapest but also the most limited option of all three, since setting it up can take days and even weeks. It can be a basic DR choice for companies that still have their IT environment on-premise and wish to have a remote Disaster Recovery solution on a colocation facility.
Warm sites
Secondly, a warm site consists of having a recovery environment available and set up to failover applications and systems in case of an emergency in the primary datacenter. Thus, it is a halfway solution between a cold and a hot site. This pre-configured recovery environment can remain either on or off.
In this case, backups and replicas must still be restored in the infrastructure reserved for Disaster Recovery. However, it requires a lower number of technical staff to do so.
Warm sites offer a balance between tolerance and affordable costs. Besides, businesses can further improve their recovery objectives by combining it with automatically geo-replicated storage snapshots.
Hot sites
Finally, a hot site is a copy of the production environment in a different infrastructure, running simultaneously with it. This option provides the highest degree of High Availability and fault tolerance, as systems are mirrored so that the recovery system takes over without any downtime in case of failure in the primary system. This configuration is also known as “active-active cluster”.
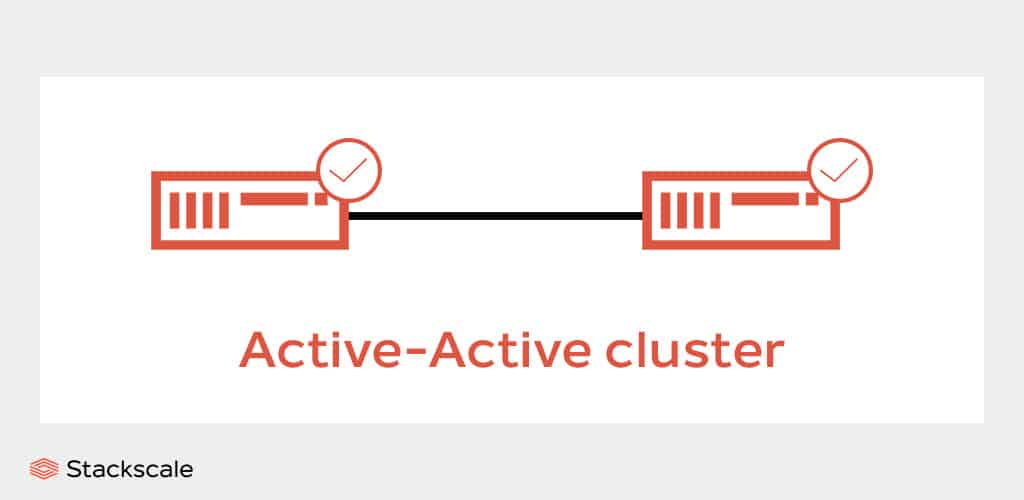
This is the optimal option for business continuity but also the most expensive one, because it requires complete redundancy in hardware and software. On the contrary, it is only necessary to check everything is running properly when systems failover to the recovery datacenter.
Hot sites are ideal for mission-critical applications that do not allow any downtime for data recovery. It is highly recommended for those companies requiring a RTO below X hours.
To sum up, regarding recovery sites, costs are inversely proportional to tolerance. As tolerance decreases, costs increase. So, the best choice for each company will depend on the risk assessment and objectives defined in their Disater Recovery plan.
| Cold site | Warm site | Hot site |
| Active environment in the main infrastructure and a reserved space in a secondary infrastructure. | Active environment in the main infrastructure and a pre-configured recovery environment in a secondary infrastructure. | Active environment in the main infrastructure and a pre-configured recovery environment turned on in a secondary infrastructure, with synchronized data. |
| Low-cost | Medium-cost | High-cost |
| High RTO | Medium RTO | Low RTO |
Geo-redundancy
Furthermore, when choosing the proper site recovery solution, geo-redundancy is another key feature to take into account to improve availability, resilience and fault tolerance. Opting for a remote, cross-datacenter recovery environment considerably improves the RTO in case of severe contingency in the main datacenter.
Relying on geographically distributed data centers contributes to building a stronger business continuity strategy. As it provides additional protection against disasters affecting the main data center.
Furthermore, regarding DR solutions at storage level, geographical redundancy must not to be neglected either. Having off-site backups is recommended to avoid data losses and improve businesses’ RPO. Data geo-replication provides an extra security layer. That is why Stackscale’s network storage volumes — Flash Premium, Hybrid Plus and Hybrid — are geo-replicated by default in a different data center.
Synchronous or Asynchronous replication
Depending on the business requirements, another aspect to consider when choosing a Disaster Recovery solution is whether it is necessary to replicate data synchronously or asynchronously to the remote location.
On the one hand, synchronous replication writes data to the primary storage and the replica simultaneously. It is to say, replication is done in real time and, therefore, the RPO equals 0. This configuration enables a failover to the Disaster Recovery solution with virtually zero downtime. That is why it is mainly used for high-end transactional applications requiring instant failover.
It is more expensive than asynchronous replication because it requires a higher amount of bandwidth and even specialized hardware.
On the other hand, asynchronous replication writes data to the replica on a scheduled basis; for example, every hour, every 6 hours or daily. So, although it can occur in near real time, it is not simultaneous. This configuration is particularly intended for working over long distances, as it can tolerate some degradation in connectivity. It is commonly used for data backups and storage snapshots, and in virtual machines.
It does not usually require specialized hardware and it requires significantly less bandwidth. Thus, its cost is lower than that of synchronous replication. However, there is a risk of data loss between the last scheduled replica and a potential incident.
Scalability
Considering scalability is also wise to ensure the company’s Disaster Recovery solution can grow along with the business needs. Organizations should never find themselves in the position to choose between which data they can back-up and which data can be left at risk, for capacity reasons.
At Stackscale, we help businesses choosing a Disaster Recovery solution adapted to their goals and requirements. Do not hesitate to contact our team for further information.