
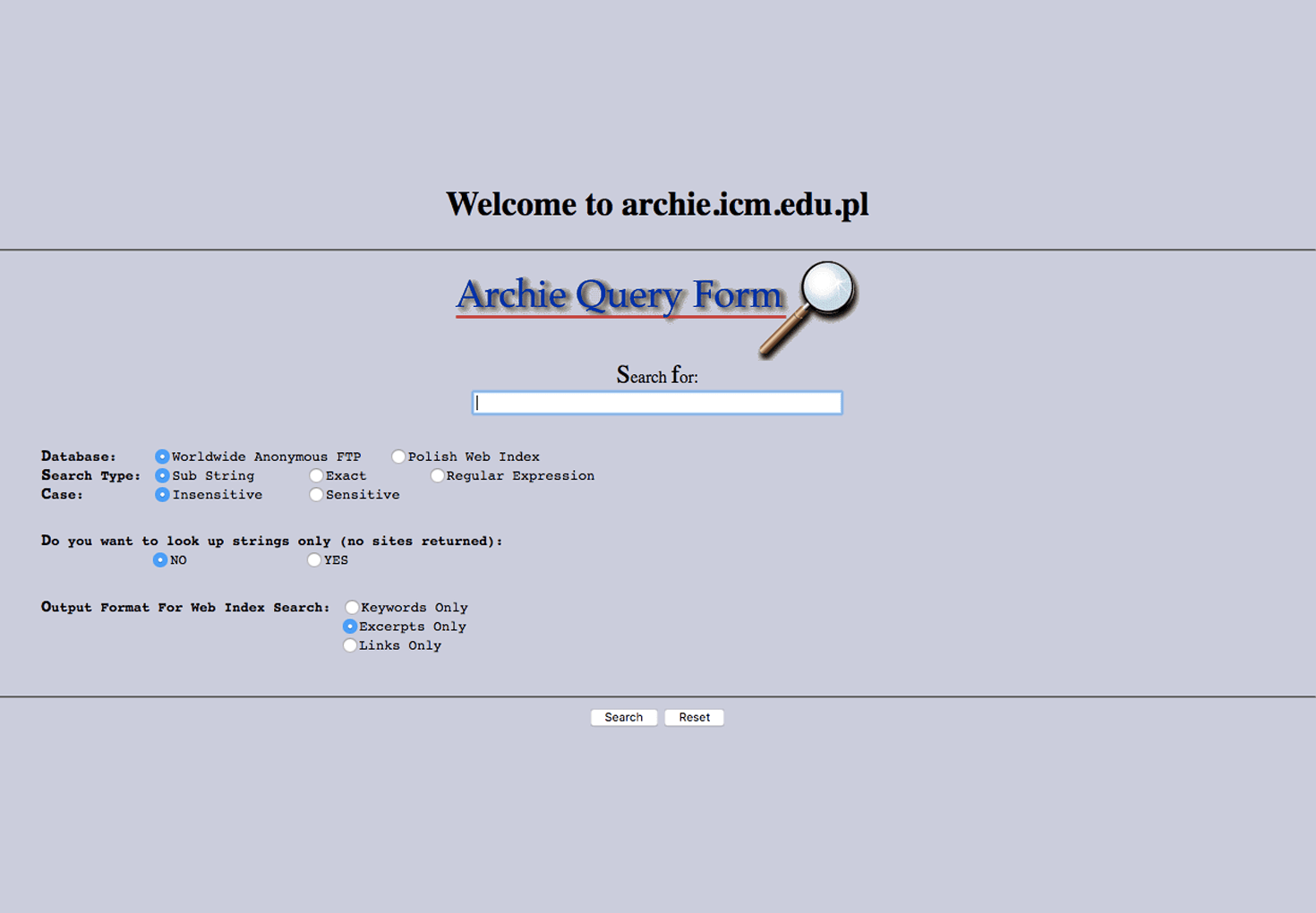
September 10, 2021 is the 31st anniversary of Archie, the first Internet search engine. Archie was launched on September 10, 1990, and developed by Alan Emtage, Bill Heelan and Peter Deutsch at McGill University in Montreal (Canada). This first search engine had nothing to do with the interactive interfaces we know. On the contrary, its interface was a simple landing page with a few search parameters.
Archie comes from the word “Archive”. However, as a curiosity, it has often been associated with the Archie comics. In fact, this association served as an inspiration for naming some search engines that came after it: Jughead and Veronica.
Jughead is the acronym for “Jonzy’s Universal Gopher Hierarchy Excavation and Display”, and Veronica is the acronym for “Very Easy Rodent-Oriented Net-wide Index to Computer Archives”. Both Jughead and Veronica were search engine systems for Gopher, a protocol developed by Mark McCahill in 1991, at the University of Minnesota.
The world’s first Internet search engine: an index of FTP files
The Archie project started with a request to connect McGill University School of Computer Science to the Internet. In short, Archie was created as an index of FTP files. It allowed users to look around the Internet. But it had limited functionalities; especially when compared to current search engines.
So, the first search engine basically was an FTP where users could make simple requests for searching files; which they had to download in order to see if it really was what they were looking for. Besides, Archie didn’t recognize natural language requests nor index the content inside the files. Therefore, users had to know the title of the file or carefully choose the term to find what they wanted. The ability to index the content inside the files was first introduced by Gopher.
Later on, the team developed several versions of Archie. Their aim was making it available at other universities, by splitting up the service. By 1993, the search engine was quite active. It had about 50K queries per day and a few thousand users around the world, as stated in this Research Problems for Scalable Internet Resource Discovery Article:
“The global collection of Archie servers process approximately 50,000 queries per day, generated by a few thousand users worldwide. Every month or two of Internet growth requires yet another replica of Archie. A dozen Archie servers now replicate a continuously evolving 150 MB database of 2.1 million records. While it responds in seconds on a Saturday night, it can take five minutes to several hours to answer simple queries during a weekday afternoon.”
From Archie to current search engines like Yahoo and Google
Over these three decades, search engines have constantly evolved until becoming the fast and easy to use tools we use now. These early search engines paved the way for creating more advanced search engines like Yahoo (1995) and Google (1997). In fact, current search engines use many techniques developed in the creation of Archie.
For historic purposes, the University of Warsaw in Poland still maintains an active legacy Archie server. This legacy server is at its Interdisciplinary Center for Mathematical and Computational Modelling (ICM).


