

High Availability or HA eliminates single points of failure in IT systems to minimize the impact of a disruption in systems, databases and applications. Thus reducing the risk of damaging productivity and losing revenue. Redundancy and automatic failure detection are key features to achieve HA.
High Availability & Operational performance
High Availability refers to an agreed level of operational performance higher than normal during a given period of time. In the event of a failure, HA infrastructures ensure minimal downtime.
Critical services in data centers require high availability to ensure systems are always available.
The level of availability is established as a percentage in SLAs (Service Level Agreements). For instance, Stackscale’s SLA guarantees 99,95% network availability and 99,90% hardware availability. Besides, the data centers where we host our infrastructure guarantee 99,99% SLA availability.
High Availability vs Fault tolerance
Both techniques are intended for delivering high levels of uptime. However, each of them achieves this goal differently:
- High Availability is achieved by putting together a set of servers. In case of failure of the primary server, one of the backup servers within the cluster will detect it and restart the service. Monitoring the environment is essential for HA.
- Fault Tolerance is achieved by mirroring systems so that the standby system takes over without any downtime when the primary system fails. It requires complete redundancy in hardware.
High Availability Metrics
As for business Disaster Recovery planning, RPO and RTO metrics are used to assess High Availability.
- RTO or Recovery Time Objective defines the maximum, acceptable duration of a failure impacting normal activity. Mission-critical applications require the lowest RTO or even zero RTO if possible.
- RPO or Recovery Point Objective defines the maximum, acceptable amount of data loss during a failure.
It is important to find the right balance between tolerance and budget to choose the right HA solution for each project. So, when measuring acceptable downtime in a business, there are some aspects to consider:
- Scheduled and unscheduled maintenance downtime.
- Hardware or software failures downtime.
- Uptime at the database and application level.
- The impact of downtime on user experience.
- Tolerable data loss.
- Business-critical applications and systems.
Mission-critical applications and systems
Mission-critical applications require the lowest RPO and RTO goals. Some business-critical systems are: CRMs, eCommerce software, supply chain management applications, BI systems, databases, etc.
Discover this case study about the importance of High Availability in eCommerce sites to support high traffic peaks and growing demand.
High Availability Clusters
HA clusters are groups of servers that work together to support mission-critical applications requiring maximum performance and minimal downtime. They feature:
- Automatic failover to a redundant system, removing single points of failure.
- Automatic detection of application-level failures.
- Zero data loss guarantee.
- Manual failover during planned maintenance tasks.
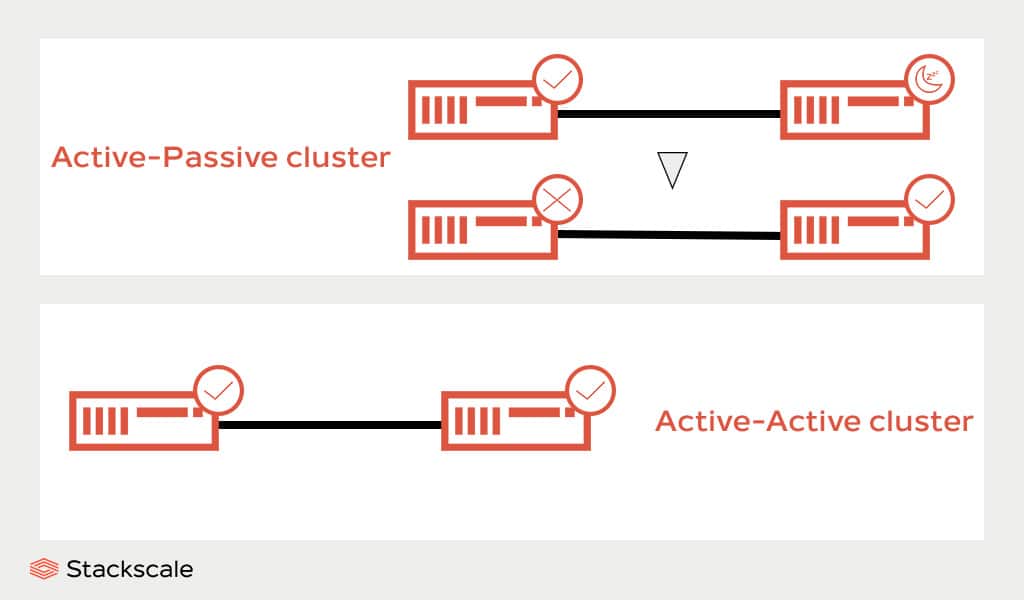
High Availability clusters ensure optimal performance during a potential failure. They are also known as “failover clusters” and they can be configured in different ways, for example:
- Active-passive clusters. In a two-nodes cluster, one of the nodes is active and the other remains on standby. Passive or takeover nodes are ready to replace the active node in case of failure.
- Active-active clusters. In a two-nodes cluster, both nodes are active simultaneously and either of them can accept read and write requests. Should one of the nodes fail, all requests would automatically go through the other active node.
High Availability architecture
A HA architecture aims to eliminate single points of failure and optimize performance during peak-time loads. Some important aspects in HA infrastructures:
- Load balancing to transmit data more efficiently and avoid server overloads.
- Geographical redundancy.
- Backup and disaster recovery strategy.
- Scalability.
- Automatic failover.
HA architecture example
High Availability can be achieved within the same datacenter, at node level, as well as relying on two geographically distant datacenters. Here is an example of HA architecture including two datacenters to further improve availability. Nodes and all network elements are redundant both in the active datacenter and in a second data center. Therefore, in case of a major contingency in the active datacenter, the second datacenter node or nodes can take over the service. Nevertheless, to ensure a zero RTO service, operating systems, databases and applications must also support this type of architecture, and must be configured accordingly.
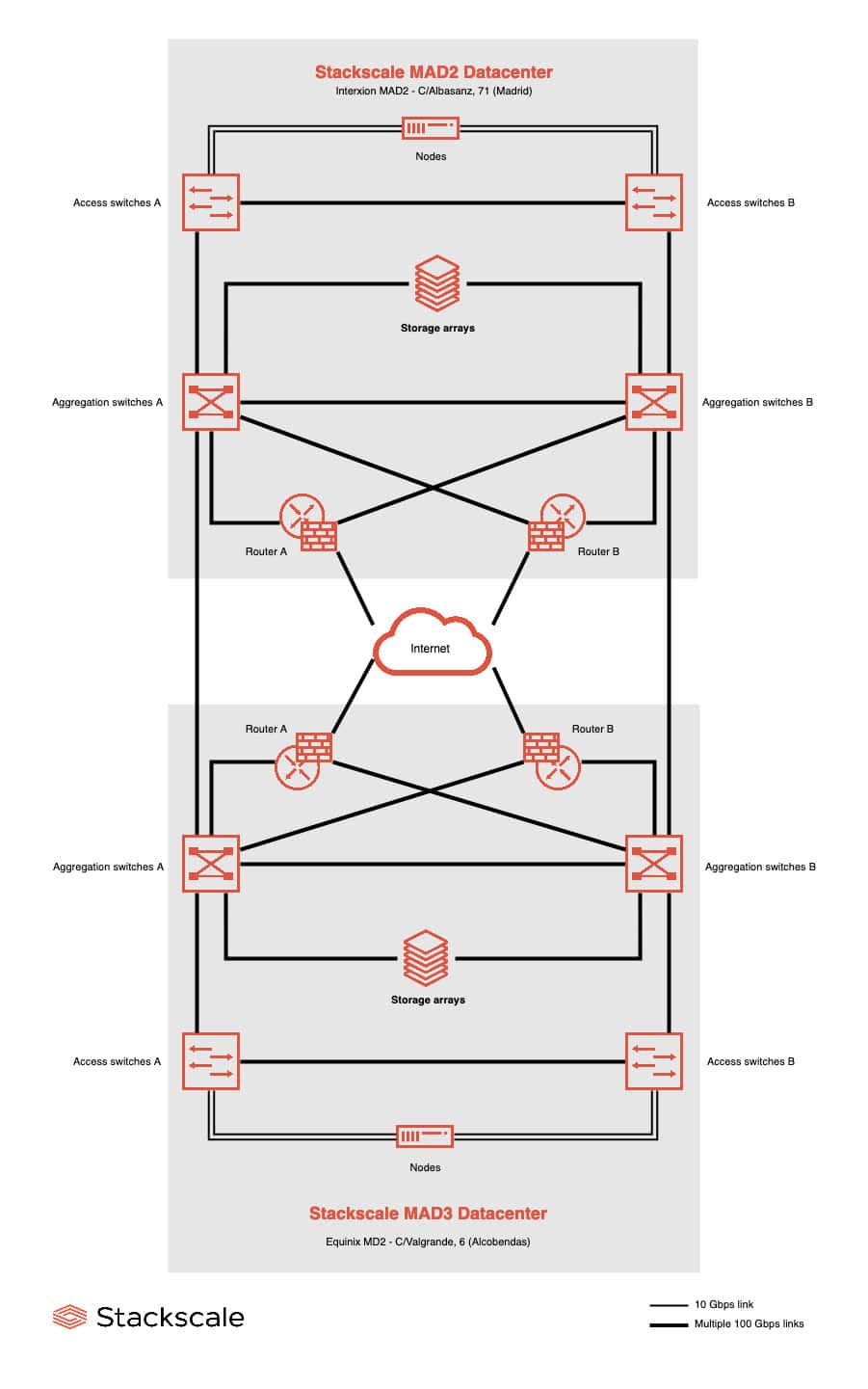
At Stackscale, we offer compute node High Availability free of charge by default, and data center redundancy as an option. Stackscale Automation and Monitoring Platform provides a quite similar level of protection to VMware High Availability. However, VMware HA requires a hot spare node within the customer cluster, whereas at Stackscale, we maintain a spare node pool available to all of our customers at no extra cost, enabling them to fully use compute nodes while keeping HA capabilities.
Finally, it is worth mentioning that relying on a High Availability infrastructure does not exempt companies from having a DR plan to maximize business continuity. On the one hand, the HA strategy allows to restore services during small, critical failures in some components. On the other hand, the Disaster Recovery strategy is necessary to overcome major events and catastrophes that can affect the datacenter.


